SQL (Structured Query Language)
관계형 데이터베이스를 조작하고 관리하기 위한 질의 언어로, RDBMS와 상호작용할 수 있는 표준적인 방법임
또한 SQL은 선언형 언어로, 어떤 데이터에 접근할지 지정하면 RDBMS가 작업 수행 방법을 결정함
SQL은 작업 수행 성격에 따라 다음과 같이 분류함
- DDL (Data Definition Language)
- 데이터베이스 객체 정의 언어
- 테이블, 뷰, 인덱스, 제약조건 등
- DCL (Data Control Language)
- 데이터베이스 객체에 대한 접근 및 권한 관리 언어
GRANT,REVOKE등
- DML (Data Manipulation Language)
- 테이블의 데이터를 조작하는 언어
INSERT,UPDATE,DELETE등
- DQL (Data Query Language)
- 데이터베이스로부터 데이터를 검색하는 언어로 DML에 포함됨
SELECT등
- TCL (Transaction Control Language)
- 트랜잭션 흐름이나 결과를 제어하는 언어
- 데이터 무결성 및 일관성 보장
DDL (Data Definition Language)
MySQL의 데이버테이스 객체를 정의하는 언어임
- 데이터베이스
- 테이블
- 제약조건
- NOT NULL
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY
- DEFAULT
- 인덱스
- 뷰
- 트리거 등
DDL의 명령어의 종류는 다음과 같음
CREATE
- 새로운 데이터베이스 객체를 생성하는 명령어
ALTER
- 기존의 데이터베이스 객체를 수정하는 명령어
DROP
- 기존의 데이터베이스 객체를 삭제하는 명령어
- 이 명령어를 실행하면 해당 객체와 관련된 모든 데이터가 영구적으로 삭제됨
TRUNCATE (테이블에만 적용되는 명령어)
- 모든 테이블의 데이터를 삭제하는 명령어
- 테이블 자체는 유지하며,
DELETE명령보다 빠르고 AUTO_INCRENMENT 값을 초기화함
RENAME
- 객체의 이름을 변경하는 명령어
COMMENT (테이블과 열에 적용되는 명령어)
- 테이블이나 열에 주석을 추가하는 명령어
- 데이터베이스 스키마를 문서화하는 데 유용함
DDL - 데이터베이스
# 생성
CREATE DATABASE my_database;
# 수정: 데이터베이스 수정은 보통 기본 문자 집합이나 정렬을 변경하는 데 사용함)
ALTER DATABASE my_database CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
# 삭제
DROP DATABASE my_database;
# 데이터베이스 이름 변경은 MySQL에서 지원되지 않음
# 새로운 데이터베이스를 생성한 뒤 데이터를 복사해서 새 데이터베이스로 이동해야 됨
DDL - 테이블
# 생성
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
position VARCHAR(100),
salary DECIMAL(10, 2)
);
# 수정 (컬럼 추가)
ALTER TABLE employees ADD COLUMN hire_date DATE NOT NULL;
# 수정 (컬럼 삭제)
ALTER TABLE employees DROP COLUMN hire_date;
# 수정 (컬럼 이름 변경)
ALTER TABLE employees RENAME COLUMN name TO full_name;
# 수정 (컬럼 데이터 타입 변경)
ALTER TABLE employees MODIFY COLUMN salary DECIMAL(12, 2);
# 수정 (컬럼 기본 값 설정)
ALTER TABLE employees ALTER COLUMN salary SET DEFAULT 0;
# 수정 (컬럼 기본 값 제거)
ALTER TABLE employees ALTER COLUMN hire_date DROP DEFAULT;
# 수정 (인덱스 추가)
ALTER TABLE employees ADD INDEX idx_name (name);
# 수정 (인덱스 제거)
ALTER TABLE employees DROP INDEX idx_name;
# 수정 (제약조건 추가)
ALTER TABLE employees ADD CONSTRAINT unique_name UNIQUE(name);
ALTER TABLE employees MODIFY COLUMN name VARCHAR(100) NOT NULL; # NOT NULL 설정
ALTER TABLE employees MODIFY COLUMN name VARCHAR(100) NULL; # NULL 설정
# 수정 (컬럼 순서 변경)
ALTER TABLE employees MODIFY COLUMN position VARCHAR(100) AFTER name;
ALTER TABLE employees MODIFY COLUMN hire_date DATE FIRST;
# 수정 (AUTO_INCREMENT 값 재설정)
ALTER TABLE employees AUTO_INCREMENT = 100;
# 수정 (테이블의 기본 문자 집합 및 정렬 방식 변경)
ALTER TABLE employees CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
# 수정 (주석 추가)
ALTER TABLE employees COMMENT = "Employee table";
ALTER TABLE employees MODIFY COLUMN salary DECIMAL(12, 2) COMMENT 'Employee salary';
# 삭제
DROP TABLE employees;
# 전체 값 삭제
TRUNCATE TABLE employees;
# 이름 변경
RENAME TABLE employees TO staff;
DDL - 인덱스
# 세컨더리 인덱스 생성
CREATE INDEX idx_name ON employees (name);
# 유니크 인덱스 생성
CREATE UNIQUE INDEX idx_unique_name ON employees (name);
# 삭제
DROP INDEX idx_name ON employees;
DROP INDEX idx_unique_name ON employees;
# 수정, 이름 변경은 인덱스 삭제 후 재생성 필요
DDL - 뷰
# 생성 (이름과 직책만 포함된 뷰 생성)
CREATE VIEW employee_view AS
SELECT name, position
FROM employees
# 수정
ALTER VIEW employee_view AS
SELECT name, position, salary
FROM employees;
# 삭제
DROP VIEW employee_view;
# 이름 변경
RENAME TABLE employee_view TO staff_view;
DDL - 트리거
# 생성
CREATE TRIGGER before_insert_employee
BEFORE INSERT ON employees
FOR EACH ROW
BEGIN
IF NEW.salary < 0 THEN
SINGAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Salary cannot be negative';
END IF;
END;
# 트리거는 수정 불가, 삭제 후 재생성
DROP TRIGGER before_insert_employee;
DCL (Data Control Language)
계정 관리
# 계정 생성
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';
# 계정 삭제
DROP USER 'username'@'localhost';
# 계정 권한 확인
SHOW GRANTS FOR 'username'@'localhost';
# 계정 이름 변경
RENAME USER 'username'@'localhost' TO 'new_username'@'localhost';
권한 부여
GRANT: 권한 부여
# 권한 부여 스니펫
GRANT 권한 종류(SELECT, UPDATE 등) ON 데이터베이스.테이블 TO 계정;
# 모든 데이터베이스에 모든 권한 부여
GRANT ALL ON *.* TO 'adam'@'localhost';
# my_database 데이터베이스의 모든 테이블에 SELECT, INSERT, UPDATE, DELETE 권한 부여
GRANT SELECT, INSERT, UPDATE, DELETE ON my_database.* TO 'username'@'localhost';
# my_database 데이터베이스의 특정 테이블에 권한 부여
GRANT SELECT, INSERT, UPDATE, DELETE ON my_database.employees TO 'username'@'localhost';
# 권한 변경 사항 적용
FLUSH PRIVILEGES;
권한 제거
REVOKE: 권한 제거
# 권한 제거 스니펫
REVOKE 권한 종류(SELECT, UPDATE 등) ON 데이터베이스.테이블 FROM 계정;
# 모든 데이터베이스에 대한 모든 권한 제거
REVOKE ALL ON *.* FROM 'adam'@'localhost';
# my_database 데이터베이스의 모든 테이블에 대한 SELECT, INSERT, UPDATE, DELETE 권한 제거
REVOKE SELECT, INSERT, UPDATE, DELETE ON my_database.* FROM 'username'@'localhost';
# my_database 데이터베이스의 특정 테이블에 대한 권한 제거
REVOKE SELECT ON my_database.employees FROM 'username'@'localhost';
# 권한 변경 사항 적용
FLUSH PRIVILEGES;
DML (Data Manipulation Language)
삽입 (INSERT)
# 단 건 삽입
INSERT INTO employees (name, position, salary)
VALUES ('john', 'manager', 75000);
# 여러 건 삽입
INSERT INTO employees (name, position, salary)
VALUES
('john', 'manager', 75000),
('anna', 'delveoper', 90000);
# 특정 열만 삽입 (나머진 기본 값 처리)
INSERT INTO employees (name)
VALUES ('mike');
# 다른 테이블의 데이터를 통해 삽입
INSERT INTO employees (name, position, salary)
SELECT name, position, salary FROM old_employees;
수정 (UPDATE)
# 특정 레코드 수정
# name이 'mike'인 레코드의 salary 값 수정
UPDATE employees
SET salary = 80000
WHERE name = 'mike';
# 여러 레코드 수정
# position이 'developer'인 모든 레코드들의 salary 값 수정
UPDATE employees
SET salary = salary * 1.05
WHERE position = 'developer';
# 모든 레코드 수정
# 조건없이 UPDATE문을 사용하면 모든 레코드의 필드가 수정됨
UPDATE employees
SET salary = 0;
# 여러 필드 수정
UPDATE employees
SET position = 'designer', salary = 60000
WHERE name = 'mike';
# 조건에 따른 수정
# salary의 값에 따라 분기 처리
UPDATE employees
SET salary = CASE
WHEN salary < 50000 THEN salary * 1.10
ELSE salary * 1.05
END;
삭제 (DELETE)
# 특정 레코드 삭제
DELETE FROM employees
WHERE name = 'mike';
# 모든 레코드 삭제
DELETE FROM employees;
DQL (Data Query Language)
DQL은 데이터베이스에 저장된 데이터를 검색하는 데 사용되는 명령어임
데이터를 추출하기 위해 필요한 절을 추가하여 필터링, 그룹화, 정렬 등을 수행할 수 있음
쿼리에 따라 적절한 인덱스를 사용하여 빠른 성능을 내거나, 느린 성능을 보여줄 수 있음
SELECT
SELECT 절은 조회된 레코드들에 대해 가져올 데이터를 선택하는 절임
이 절을 통해 특정 컬럼이나 컬럼들의 집합을 선택하여 결과를 가져올 수 있음
SELECT 절에 명시할 수 있는 항목들
컬럼 이름
- 테이블의 특정 컬럼을 선택함
SELECT first_name FROM users;
와일드 카드
- 테이블의 모든 컬럼을 선택함
SELECT * FROM users;
별칭
- AS 키워드를 사용하여 컬럼에 별칭을 지정함
SELECT first_name AS fname FROM users;
표현식
- 컬럼 간의 계산이나 문자열 연결 등의 표현식을 사용할 수 있음
SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM users;
집계 함수
- COUNT, SUM, AVG, MAX, MIN 등의 집계 함수를 사용하여 결과를 집계할 수 있음
SELECT COUNT(*) FROM users;
DISTINCT
- 중복된 값을 제거하고 유일한 값만 선택함
SELECT DISTINCT country FROM users;
서브쿼리
- 다른 쿼리의 결과를 가져옴
SELECT (SELECT MAX(age) FROM users) AS max_age;
CASE문
- 조건에 따라 값을 선택하는 논리 연산 수행
-
SELECT first_name, last_name, CASE WHEN gender = 'M' THEN 'Male' WHEN gender = 'F' THEN 'Female' ELSE 'Other' END AS gender_description FROM users;
FROM
FROM 절은 데이터를 가져올 테이블이나 뷰를 지정하는 데 사용되는 절임
SELECT 절이 어떤 데이터를 가져올 지 결정한다면, FROM 절은 그 데이터의 원천을 지정한다고 볼 수 있음
FROM 절에 명시할 수 있는 항목들
단일 테이블
- 하나의 테이블 지정
SELECT * FROM users;
여러 테이블
- 쉼표로 구분하여 여러 테이블을 지정할 수 있으나, 명시적으로 JOIN을 사용하는 게 더 명확함
SELECT * FROM users, orders;
서브 쿼리
- FROM 절 안에서 서브쿼리를 사용하는 경우, 가상 테이블을 생성하는 것과 같은 효과를 가짐
-
SELECT greater_equal_thirty_user.name FROM ( SELECT first_name AS name FROM users WHERE age > 30 ) AS greater_equal_thirty_user
뷰
- 뷰는 하나 이상의 테이블에 대한 쿼리 결과를 가상의 테이블처럼 사용하는 것임
SELECT * FROM active_users_view;
JOIN
FROM 절에서 2개 이상의 테이블을 연결하여 데이터를 조회하는 방법으로
테이블 간의 관계를 설정하고 그 관계를 기반으로 데이터를 결합하여 하나의 결과 집합만듦
데이터의 일관성을 유지하고, 중복된 데이터를 생성하지 않기 위해 조인을 사용함
조인 종류
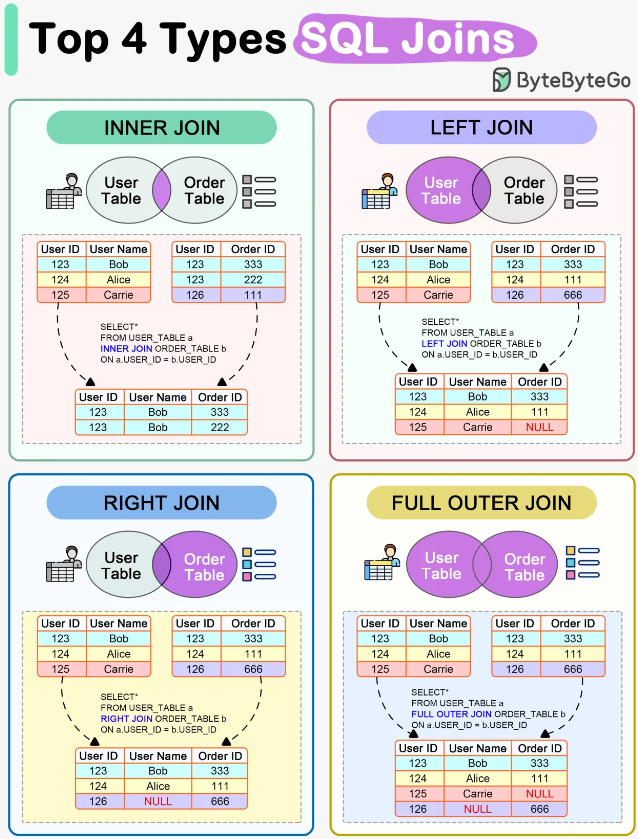
출처 ByteByteGo
ON절
- 테이블 간의 조건을 명시하는 데 사용됨
- 두 테이블을 결합할 때 어떤 컬럼들이 서로 일치해야 하는지를 지정함
INNER JOIN
- 테이블 간에 일치하는 데이터만 반환함
- 조인 조건에 부합하는 행들만 결과 집합에 포함됨
- JOIN만 명시한 경우 INNER JOIN으로 처리됨
LEFT JOIN (LEFT OUTER JOIN)
- 왼쪽 테이블의 모든 데이터를 반환하고, 오른쪽 테이블에서 일치하는 데이터가 있는 경우 그 데이터를 함께 반환
- 오른쪽 테이블에 일치하는 데이터가 없으면 NULL로 채워짐
RIGHT JOIN (RIGHT OUTER JOIN)
- 오른쪽 테이블의 모든 데이터를 반환하고, 왼쪽 테이블에서 일치하는 데이터가 있는 경우 그 데이터를 함께 반환
- 왼쪽 테이블에 일치하는 데이터가 없으면 NULL로 채워짐
FULL JOIN (FULL OUTER JOIN)
- 두 테이블의 모든 데이터를 반환함
- 일치하는 데이터가 있으면 결합하고, 그렇지 않으면 NULL로 채워짐
- MySQL에선 기본적으로 지원되지 않으며, 이를 구현하려면 UNION을 사용해야 함
-
SELECT * FROM user_table a LEFT JOIN order_table b ON a.user_id = b.user_id UNION SELECT * FROM user_table a RIGHT JOIN order_table b ON a.user_id = b.user_id;
CROSS JOIN (CARTESIAN PRODUCT)
- 두 테이블의 모든 행에 대해 모든 조합을 생성함
- 반환된 결과 집합의 행 수는 두 테이블의 행 수를 곱한 값이 됨
- 카디션 곱이라고도 함
-
SELECT * FROM user_table CROSS JOIN order_table;
SELF JOIN
- 동일한 테이블을 두 번 참조하여 조인함
- 테이블 내에 조인할 수 있는 컬럼이 있는 경우에 사용됨
-
SELECT a.first_name AS mentor, b.first_name AS mentee FROM users a JOIN users b ON a.user_id = b.mentor_id
WHERE
WHERE 절은 조건을 지정하여, 그 조건을 만족한 행들만 결과로 반환하도록 필터링하는 절로 SELECT, UPDATE, DELETE와 같은 쿼리에서 사용됨
기본적으로 쿼리는 테이블의 모든 행을 반환하거나 처리하게 되므로 불필요한 데이터를 걸러내려면 필터링이 꼭 필요함
WHERE 절에서 사용할 수 있는 조건들
동등 비교 조건 (Equal Comparison)
=,!=,<>SELECT * FROM users WHERE age >= 30;
값 체크 (Value Checking)
IN: 지정된 값들 중 하나와 일치하는 행을 찾음SELECT * FROM users WHERE job IN ('Backend', 'Frontend', 'Infra')
IS NULL,IS NOT NULL: 값이 NULL 인지 또는 NULL이 아닌지 확인SELECT * FROM users WHERE phone_number IS NULL;- EXISTS
- 서브쿼리의 결과가 존재하는지 확인하여, 존재하면 행을 반환함
- EXISTS는 서브쿼리가 결과를 반환할 떄 TRUE, 그렇지 않으면 FALSE를 반환함
-
# 사용자가 하나 이상의 주문을 가지고 있는 경우 EXISTS는 TRUE를 반환 SELECT * FROM users WHERE EXISTS ( # 서브쿼리에서 선택되는 값은 중요하지 않으므로 1을 선택 SELECT 1 FROM orders WHERE users.user_id = orders.user_id ) -
# 특정 제품(product_id=123)을 주문한 고객을 반환 SELECT user_id FROM users WHERE EXISTS ( SELECT 1 FROM orders WHERE orders.customer_id = customers.customer_id AND orders.product_id = 123 )
범위 검색 (Range Searching)
BETWEEN: 두 값 사이에 있는지를 확인함SELECT * FROM users WHERE age BETWEEN 20 AND 30;
<,>,<=,>=: 값이 특정 범위에 속하는지를 확인함SELECT * FROM users WHERE age > 20;SELECT * FROM users WHERE age <= 30;
LIKE: 문자열이 특정 패턴과 일치하는 지 확인함,%는 0개 이상의 임의의 문자를,_는 1개의 임의의 문자를 의미함SELECT * FROM users WHERE name LIKE 'A%';
논리 연산자 (Logical Operators)
- AND
- OR
- NOT
SELECT * FROM users WHERE age >= 30 AND job = 'Developer';
서브 쿼리
- WHERE 절 내에서 다른 쿼리를 서브 쿼리로 사용하여 조건을 지정할 수 있음
-
SELECT * FROM users WHERE age > (SELECT AVG(age) FROM users); # 평균 나이보다 많은 나이를 가진 유저 필터링
GROUP BY
GROUP BY 절은 데이터의 특정 컬럼을 기준으로 그룹화하고, 각 그룹에 대해 집계(합계, 평균, 개수 등)를 수행할 때 사용됨
데이터를 분석하거나 특정 범주에 대한 요약된 정보를 얻고자 할 때 유용함
특징
- GROUP BY는 지정된 컬럼의 값과 동일한 행들을 하나의 그룹으로 묶음
- 각 그룹에 대해 집계 함수 적용 가능
- SELECT 절에는 GROUP BY 절에서 지정된 컬럼과 집계 함수를 사용하는 컬럼만 포함될 수 있음
# 각 부서 별로 직원 수를 계산
SELECT deparment, COUNT(*)
FROM employees
GROUP BY department;
# 주문 카테고리 별로 주문된 총 수량을 계산
SELECT category, SUM(quantity) AS total_quantity
FROM orders
GROUP BY category;
# 부서와 직무 별로 평균 급여 계산
SELECT deparment, job, AVG(salary) AS average_salary
FROM employees
GROUP BY deparment, job;
HAVING
HAVING 절은 WHERE 절과 유사하게, GROUP BY 절로 그룹화된 결과에 필터링을 적용하는 데 사용됨
GROUP BY절과 마찬가지로 GROUP BY 절에 지정된 컬럼과 집계 함수를 사용하는 컬럼만 포함할 수 있음
# 직원 수가 10명 이상인 부서만 결과로 반환
SELECT deparment, COUNT(*) AS num_employees
FROM employees
GROUP BY deparment
HAVING COUNT(*) >= 10;
# 부서 별로 평균 급여를 계산하고, 평균 급여가 50000이면서 부서가 'Dev'인 경우만 결과로 반환
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY deparment
HAVING AVG(salary) >= 50000 AND deparment = 'Dev';
ORDER BY
ORDER BY 절은 SQL 쿼리의 결과를 특정 컬럼이나 표현식을 기준으로 정렬할 때 사용됨
특징
- 기본적으로 오름차순으로 정렬됨
- 여러 개의 컬럼을 지정할 수 있으며, 첫 번째 컬럼을 기준으로 우선 정렬한 후 두 번째 컬럼으로 정렬함
- 오름차순: 숫자의 경우 작은 값에서 큰 값, 알파벳의 경우 A부터 Z 순으로 정렬
- 내림차순: 숫자의 경우 큰 값에서 작은 값, 알파벳의 경우 Z부터 A 순으로 정렬
# 사용 방법
SELECT column1, column2
FROM table_a
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC];
# first_name은 오름차순으로, last_name은 내림차순으로 정렬
SELECT first_name, last_name
FROM users
ORDER BY first_name, last_name DESC
LIMIT
쿼리의 전체 결과에서 특정 개수의 행만 반환하도록 제한하는 데 사용됨
# 사용 방법
SELECT column1, column2
FROM table_a
ORDER BY column_name
LIMIT [offset,] row_count;
# offset: 반환할 첫 번째 행의 위치를 지정(0부터 시작하며, 생략할 시 기본 값은 0이 됨
# row_count: 반환할 최대 행 수를 지정
# users 테이블의 처음 5개의 행만 반환
SELECT *
FROM users
LIMIT 5;
# 나이가 많은 순서대로 정렬한 후, 11번째 행부터 5개의 행을 반환(오프셋은 0부터 시작하므로 OFFSET 10은 11번째 행을 의미)
SELECT name, age
FROM users
ORDER BY age DESC
LIMIT 10, 5; # LIMIT 5 OFFSET 10와 동일
SQL 실행 순서
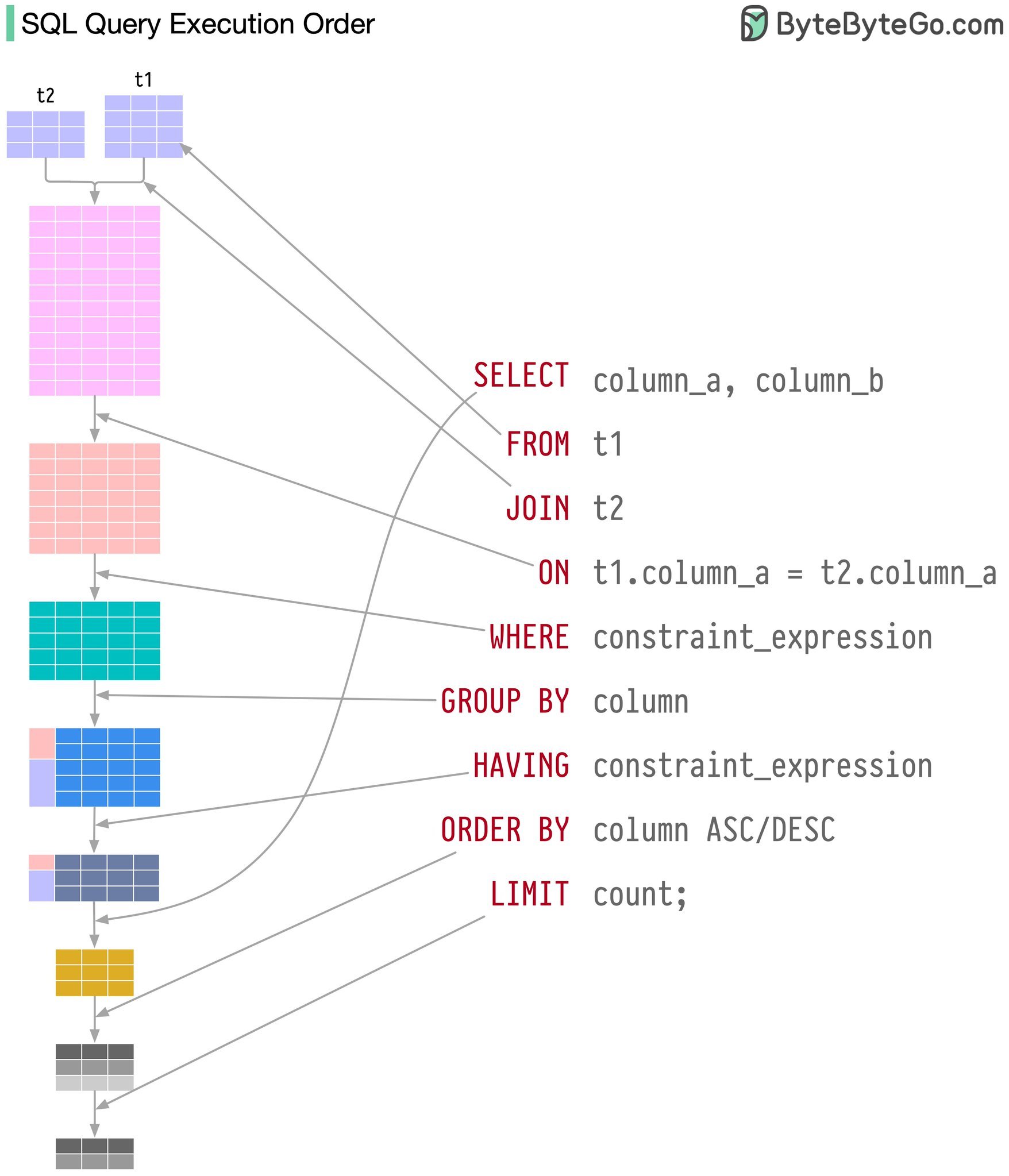
출처 ByteByteGo
FROM -> JOIN -> ON -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> LIMIT 순서로 쿼리가 실행됨
TCL (Transaction Control Language)
TCL은 데이터베이스에서 트랜잭션을 제어와 관리에 사용되는 SQL 명령어임
트랜잭션은 데이터베이스 무결성과 일관성을 보장하기 위해 SQL 연산을 하나의 논리적인 단위로 묶어 처리하는 것을 말함
COMMIT
트랜잭션을 데이터베이스에 영구히 반영하는 명령어
이 명령어를 실행하면, 현재 트랜잭션 내의 모든 변경사항이 확정되며, 롤백을 할 수 없게 됨
# 트랜잭션 시작
START TRANSACTION
# 데이터 작업 ...
# 변경사항 반영
COMMIT
ROLLBACK
현재 트랜잭션에서 이뤄진 모든 변경사항을 취소하고, 데이터베이스를 트랜잭션 시작 전의 상태로 되돌림
# 트랜잭션 시작
START TRANSACTION
# 데이터 작업 ...
# 원 상태로 복구
ROLLBACK
SAVEPOINT
트랜잭션 내에서 특정 시점에 저장점을 설정하여, 해당 시점 이후의 변경사항만 롤백할 수 있도록 함
START TRANSACTION
# 데이터 작업 1 ...
SAVEPOINT savepoint1;
# 데이터 작업 2 ...
# savedpoint1 이후의 작업만 취소 (데이터 작업 1은 롤백하지 않음)
ROLLBACK savepoint1;
COMMIT
SET TRANSACTION
트랜잭션의 격리 수준과 같은 특성을 설정하는 데 사용됨
# 트랜잭션 시작 및 격리 수준 설정
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
START TRANSACTION;
# 데이터 작업 ...
COMMIT;