ArrayList
배열의 크기를 조정할 수 있는 List 인터페이스 구현체
- List 인터페이스의 모든 optional 작업 구현
- element 타입으로 모든 타입을 받음 (null 포함)
- 요소를 삽입하기 전에 내부적으로 공간이 부족한 지 확인 후 삽입 (부족하다면 길이 조정)
주의사항
- ArrayList는 동기화되지 않음
여러 스레드에서 동일한 ArrayList에 접근해서 삽입/삭제/크기 조정한다면 데이터 손실이나 예외가 발생함
(요소의 값을 바꾸는 건 해당되지 않음)
따라서 ArrayList 외부에서 동기화를 보장하거나 thread-safe 리스트 구현체를 사용해야 됨
- ArrayList의
iterator,listIterator메서드에서 반환한 iterator는 빠른 실패(fail-fast)를 일으킬 수 있음
iterator가 생성된 후로 다른 스레드에서 ArrayList를 삽입/삭제 등의 작업을 수행하면 (다만 iterator 자체적으로 삽입/삭제 등의 작업은 예외)
추후에 애매한 상황을 만들지 않고자 바로 ConcurrentModificationException을 터뜨림
동시성 이슈 해결방안
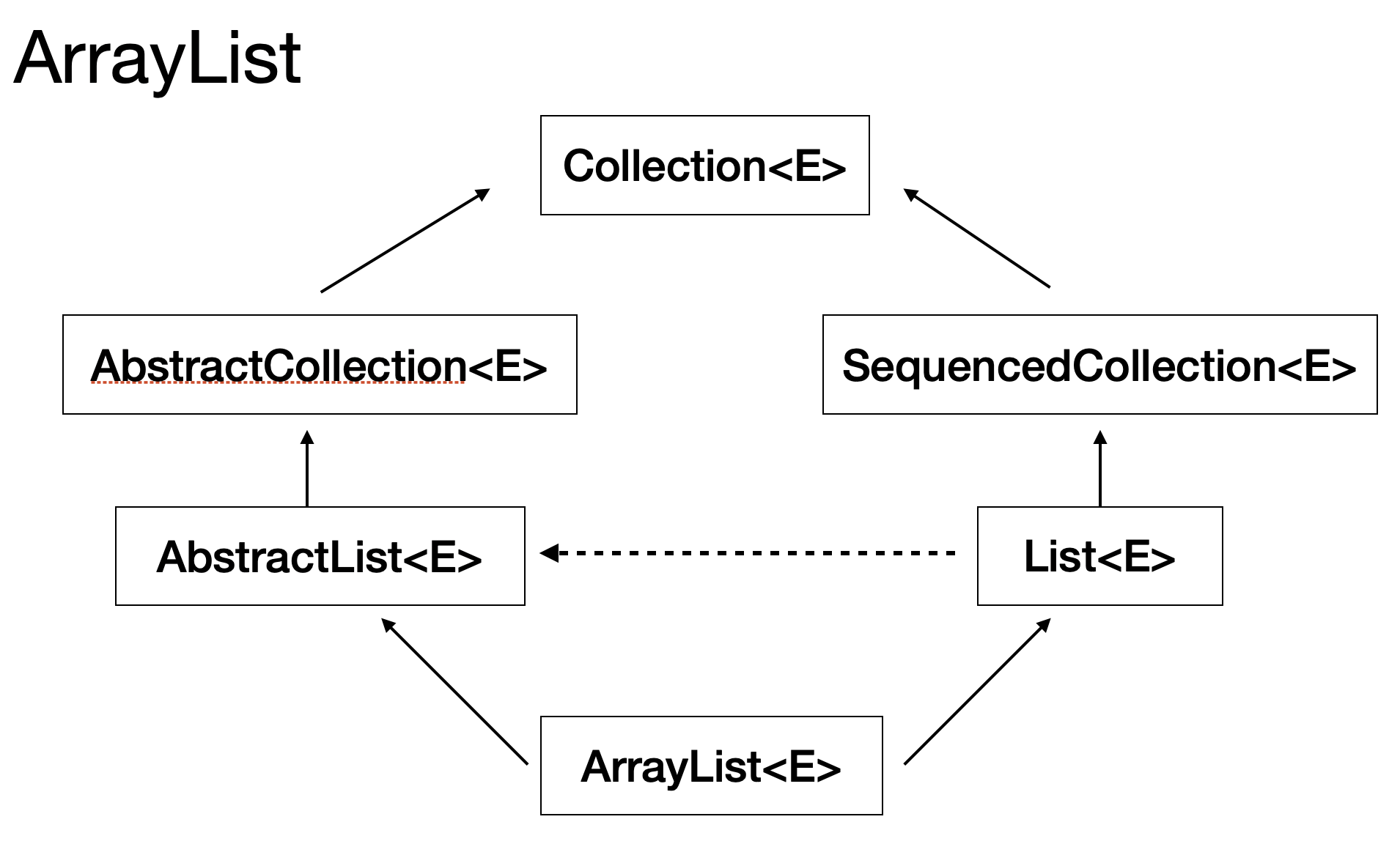
ArrayList 분석
계층 구조
주요 필드
// 기본 용량
private static final int DEFAULT_CAPACITY = 10;
// ArrayList 요소가 저장되는 필드
Object[] elementData;
// 현재 저장된 요소의 개수
private int size;
메서드 목록
- add, addAll, addFist, addLast
- remove, removeAll, removeFirst, removeLast, removeIf
- retainAll, replaceAll
- set, get, getFist, getLast, subList, indexOf
- grow, trimToSize, ensureCapacity
- clone, toArray, clear
생성자
기본 생성자, capacity를 받는 생성자는 간단해서 제외
Collection 타입을 매개변수로 받는 생성자(Collection -> ArrayList)
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
위의 코드에서 주의깊게 볼 부분
-
c.getClass() == ArrayList.classc.getClass().isAssignableFrom(ArrayList.class)대신 직접 비교를 하는 코드를 사용isAssignableFrom()은 상속 관계를 검사하는데 사용함
상대적으로 느린 메서드를 사용하지 않고 정확한 타입을 비교하기 위해
==연산자 사용 -
elementData = Arrays.copyOf(a, size, Object[].class)위에서
Object[] a = c.toArray()로 매개변수로 받은 Collection 구현체를 배열로 변환한 후해당 배열을 복사한 새로운 Object[] 배열을 ArrayList의 필드에 할당함
Collection 구현체의 배열을 그대로 사용할 경우 외부에서 수정될 위험이 있으므로 데이터 무결성을 보장하기 위함임
grow (동적 배열 크기 조정)
자동으로 ArrayList가 가진 배열의 크기를 스스로 조정하는 메서드
ArrayList의 가장 핵심이지 않나 싶음
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
현재 배열의 크기를 oldCapacity에 할당 후, 분기 처리
- 요소를 가지고 있는 경우(oldCapacity > 0)
- ArraysSupport.newLength()를 통해 새로운 배열의 크기를 정하고, Arrays.copyOf()를 통해 기존의 배열보다 길이가 길어진 값이 복사된 새 배열을 할당함
- 없는 경우
- grow() 매개변수로 받은 값과 DEFAULT_CAPACITY 중 큰 값을 크기로 갖는 새 배열 할당
ArraysSupport는 jdk.internal.util 패키지에 속한 클래스로 jdk 내부적으로만 사용할 수 있는 클래스임
// package jdk.internal.util;
// ArraysSupport.newLength()
public static final int SOFT_MAX_ARRAY_LENGTH = Integer.MAX_VALUE - 8;
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
int prefLength = oldLength + Math.max(minGrowth, prefGrowth); // might overflow
if (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) {
return prefLength;
} else {
// put code cold in a separate method
return hugeLength(oldLength, minGrowth);
}
}
private static int hugeLength(int oldLength, int minGrowth) {
int minLength = oldLength + minGrowth;
if (minLength < 0) { // overflow
throw new OutOfMemoryError(
"Required array length " + oldLength + " + " + minGrowth + " is too large");
} else if (minLength <= SOFT_MAX_ARRAY_LENGTH) {
return SOFT_MAX_ARRAY_LENGTH;
} else {
return minLength;
}
}
// oldLength: 현재 배열의 크기
// minGrowth: 최소 증가량
// prefGrowth: 선호 증가량
- 최소 증가 길이와 선호 증가 길이 중 큰 값과 현재 배열의 크기를 더한 값이 기준에 적합하다면 이 값을 리턴함
- 그렇지 않은 경우 hugeLength()를 통해 현재 배열 크기와 최소 증가 길이를 더한 값이
SOFT_MAX_ARRAY_LENGTH보다 작거나 동일하다면SOFT_MAX_ARRAY_LENGTH(Integer.MAX_VALUE - 8)의 값을 리턴함
private Object[] grow() {
return grow(size + 1);
}
add()에서 grow()를 호출하는데, grow()는 다시 grow(size + 1)을 호출함
즉, grow(int minCapacity)의 매개변수 값은 현재 배열이 가진 요소의 개수에 1을 더한 값임
따라서 newLength()에 전달되는 minGrowth의 값은 (전체 요소 개수 + 1) - 배열의 길이(메모리에 할당된 공간의 크기)가 되고
prefGrowth의 경우 oldCapacity >> 1 비트 연산자를 사용해서 오른쪽으로 1비트씩 이동(shift)하고 있는데 이건 2로 나눈 값과 동일한 값으로, 배열의 절반 길이의 값임
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
add 메서드에서 값을 넣기 전에 전체 요소의 개수가 배열의 길이와 동일한 경우 grow()를 호출하는데,
grow()에서 size+1을 값으로 전달하기에 newLength에 전달되는 minGrowth의 값은 항상 1이 되므로, 배열 길이의 절반 값을 가진 prefGrowth가 항상 큰 걸 알 수 있음
고로 ArrayList는 내부적으로 배열 길이를 늘릴 때, 자신의 배열 길이의 절반을 늘린다는 것을 알 수 있음
삽입
삽입 메서드: add, addAll, addFirst, addLast
요소만 전달해서 삽입하는 경우
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
요소만 전달받는 경우 내부적으로 add()를 호출하고 있음
add(E e, Object[] elementData, int s)는 add(E e)에서만 사용하는 걸로 봐서 재사용성을 염두에 둔 게 아닌 것 같은데
굳이 내부적으로 add 메서드를 한 번 더 호출하는 이유가 뭘까?
JIT 컴파일러는 메서드 인라이닝이라는 성능 최적화 기법을 제공함
런타임에 자주 호출되는 메서드를 분석해서 메서드의 크기와 호출 빈도를 기반으로 인라이닝을 결정하는데,
메서드 인라이닝이 적용되면 메서드 호출 지점에 메서드의 실제 코드로 대체함
만약 다음과 같이 1백만 번의 add 메서드를 호출하는 코드가 있다고 가정해보면
for (int i; i<1_000_000; i++) {
add(i);
}
for문의 add(E e)를 호출이 다음과 같이 변경됨
for (int i = 1; i <= 1_000_000; i++) {
modCount++;
add(i, elementData, size);
}
그리고 add(e, elementData, size)는 다시 메서드 인라이닝이 적용됨
for (int i; i<1_000_000; i++) {
modCount++;
if (s == elementData.length) {
elementData = grow();
}
elementData[s] = i;
size = s + 1;
}
메서드 인라이닝이 적용되려면 메서드의 크기를 줄여야되기 때문에 add(E e)와 add(E e, Object[] elementData, int s)를 분리해놓음
(C1 컴파일 루프 문에서 바이트코드 사이즈가 35(-XX:MaxInlineSize 기본 값) 이하인 경우)
이러한 메서드를 헬퍼 메서드라고 함
인덱스를 지정해서 삽입하는 경우
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}
index 범위 확인 후 modCount 변경
현재 배열 길이와 size가 동일한 경우 grow()를 호출하고
인덱스부터 (size - index) 길이만큼 한 칸씩 뒤로 이동시킨 후 삽입
컬렉션을 전달해서 삽입하는 경우
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
System.arraycopy(a, 0, elementData, s, numNew);
size = s + numNew;
return true;
}
매개변수로 받은 컬렉션 구현체를 배열로 변환한 후 길이가 0이라면 리턴
아니라면 현재 삽입 가용한 길이보다 컬렉션 배열의 길이가 더 큰지 확인하고, 길다면 grow() (minCapacity: 현재 배열의 크기와 컬렉션 길이를 합한 값) 호출
이후 컬렉션 배열을 size 인덱스부터 삽입
맨 처음과 맨 마지막에 삽입하는 경우
public void addFirst(E element) {
add(0, element);
}
public void addLast(E element) {
add(element);
}
addFirst의 경우 인덱스 0을 지정해서 요소를 삽입(나머지 모든 요소는 한 칸씩 이동)하고
addLast의 경우 add(E e)를 호출해서 size 인덱스에 요소를 삽입함
삭제
삭제 메서드: remove, removeAll, removeFirst, removeLast, removeIf, clear
remove
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
fastRemove(es, i);
return true;
}
특정 인덱스에 위치한 요소 또는 배열에 있는 특정 요소를 직접 지정해서 삭제할 때 remove를 사용함
인덱스를 전달하는 경우엔 인덱스의 범위가 적절한지 검증한 뒤 fastRemove 메서드를 호출해서 삭제 처리를 하고
오브젝트를 전달하는 경우엔 루프를 돌아 배열 안에 해당하는 값이 있는지 찾음 O(n)
있는 경우엔 인덱스 전달과 마찬가지로 fastRemove 메서드를 호출하고, 없는 경우엔 false를 리턴해서 삭제 실패를 나타냄
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}
실제로 배열의 특정 요소를 삭제하는 로직을 가진 헬퍼 메서드
객체 배열과 삭제할 인덱스를 매개변수로 받음
(size - 1)의 값이 삭제할 인덱스 값보다 큰 경우(남은 요소들의 위치를 옮겨야 되는 경우)엔
삭제할 인덱스의 다음 위치의 요소들을 한 칸씩 땡긴 후 맨 마지막에 남은 한 자리를 null 처리함
즉, 삭제할 인덱스의 값은 다음 요소에 의해 덮어씌워지고 이렇게 한 칸씩 자리를 옮기면 남은 한 자리가 발생할테니 이 부분의 값을 비워줌
removeAll
public boolean removeAll(Collection<?> c) {
return batchRemove(c, false, 0, size);
}
removeAll 메서드는 매개변수로 받은 컬렉션의 요소 중 배열에 포함된 요소를 삭제함
retainAll
public boolean retainAll(Collection<?> c) {
return batchRemove(c, true, 0, size);
}
retainAll 메서드는 removeAll과 반대로, 매개변수로 받은 컬렉션의 요소 중 배열에 포함된 요소를 제외한 나머지 요소들을 삭제함
두 메서드 모두 batchRemove 헬퍼 메서드를 호출함
boolean batchRemove(Collection<?> c, boolean complement,
final int from, final int end) {
...
}
batchRemove는 컬렉션 c와 complement 플래그를 사용해서 주어진 범위(from, end)의 요소들을 삭제하거나 유지하는 역할을 하는 메서드임
매개변수 complement는 batchRemove 메서드의 동작을 제어하는 역할을 가짐
removeAll()의 경우 complement의 값을 false로 지정하여 컬렉션에 포함된 요소들을 제거함
retainAll()의 경우 complement의 값을 true로 지정하여 컬렉션에 포함된 요소들을 유지함
메서드의 로직을 부분적으로 나눠서 살펴보자
boolean batchRemove(Collection<?> c, boolean complement,
final int from, final int end) {
Objects.requireNonNull(c);
final Object[] es = elementData;
int r;
// Optimize for initial run of survivors
for (r = from; ; r++) {
if (r == end)
return false;
if (c.contains(es[r]) != complement)
break;
}
...
}
지역변수 r(read index)은 현재 위치를 가리킨는데, 배열 elementData의 요소들을 순회하면서 조건에 맞는 요소를 찾음
첫 루프문은 초기 서바이벌 런 최적화라고 주석 처리되어있는데, complement의 조건에 만족하는 첫 번째 요소를 찾는 과정임
removeAll의 경우 컬렉션에 포함된 elementData(ArrayList의 배열)의 첫 번째 요소를 찾고 (c.contains(es[r]) != complement는 c.contains(es[r]) == true와 동일)
retainAll의 경우 컬렉션에 포함되지 않은 elementData의 첫 번째 요소를 찾음 (c.contains(es[r]) != complement는 c.contains(es[r]) == false와 동일)
boolean batchRemove(Collection<?> c, boolean complement,
final int from, final int end) {
...
int w = r++;
try {
for (Object e; r < end; r++)
if (c.contains(e = es[r]) == complement)
es[w++] = e;
} catch (Throwable ex) {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
System.arraycopy(es, r, es, w, end - r);
w += end - r;
throw ex;
} finally {
modCount += end - w;
shiftTailOverGap(es, w, end);
}
return true;
}
그렇게 조건에 맞는 첫 번째 요소를 찾으면 그 다음은 조건에 충족하는 요소들만 새로운 위치의 인덱스에 값을 복사하는 과정을 거침
지역변수 w(write index)는 새로운 배열의 위치를 나타내는 인덱스임
r(첫 번째 요소를 찾은 다음 인덱스 위치)부터 end까지 루프를 돌면서 조건에 맞는 요소들을 w 위치로 복사함
removeAll의 complement 값은 false이므로, c.contains(e = es[r])의 값이 false인 경우(컬렉션에 값이 포함되지 않는 경우)
retainAll의 complement 값은 true이므로, c.contains(e = es[r])의 값이 true인 경우(컬렉션에 값이 포함된 경우)에 w 위치로 복사함
예외가 발생하면 현재 위치인 r에서 end까지의 요소들을 w에 복사하고 다시 예외를 던짐
최종적으로 shiftTailOverGap(es, w, end)를 호출하여 배열의 나머지 부분을 정리함
private void shiftTailOverGap(Object[] es, int lo, int hi) {
System.arraycopy(es, hi, es, lo, size - hi);
for (int to = size, i = (size -= hi - lo); i < to; i++)
es[i] = null;
}
shiftTailOverGap은 배열에서 제거된 요소들로 인해 생긴 갭을 메우기 위해 나머지 요소들을 앞으로 이동시키고, 끝부분을 null로 채움
removeFirst, removeLast
public E removeFirst() {
if (size == 0) {
throw new NoSuchElementException();
} else {
Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[0];
fastRemove(es, 0);
return oldValue;
}
}
public E removeLast() {
int last = size - 1;
if (last < 0) {
throw new NoSuchElementException();
} else {
Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[last];
fastRemove(es, last);
return oldValue;
}
}
각각 검증 로직을 거친 뒤 fastRemove() 호출
clear
public void clear() {
modCount++;
final Object[] es = elementData;
for (int to = size, i = size = 0; i < to; i++)
es[i] = null;
}
요소를 순회하면서 null 처리
clone
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
super.clone()
- 자기 자신 복사(shallow-copy)
- ArrayList는
Cloneable을 명시하고, Object.clone()을 오버라이딩하고 있음
Arrays.copyOf()
- 요소 복사
- Arrays.copyOf()는 내부적으로 System.arraycopy()를 호출함
toArray
매개변수가 없는 경우
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
자기 자신의 요소들을 복사하여 반환
T[] 타입의 배열 매개변수가 있는 경우
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
매개변수의 길이에 따른 분기 처리
- 매개변수 배열의 길이가 ArrayList의 배열에 담긴 요소 개수보다 작은 경우
- 새로운 a 타입의 배열을 만들고 자기 자신의 요소들을 복사 후 반환
- 아닌 경우
- 매개변수로 받은 배열에 자기 자신의 요소들을 복사 후 반환
- 만약 매개변수 배열의 길이가 ArrayList의 size보다 큰 경우 맨 마지막 index에 null 처리
Iterator
add나 remove처럼 리스트의 크기(size)를 변경시키는 구조적 수정(structural modification) 메서드의 경우
iterator의 fail-fast를 제공하기 위해 modCount를 사용함