LinkedList 특징 및 상속 관계
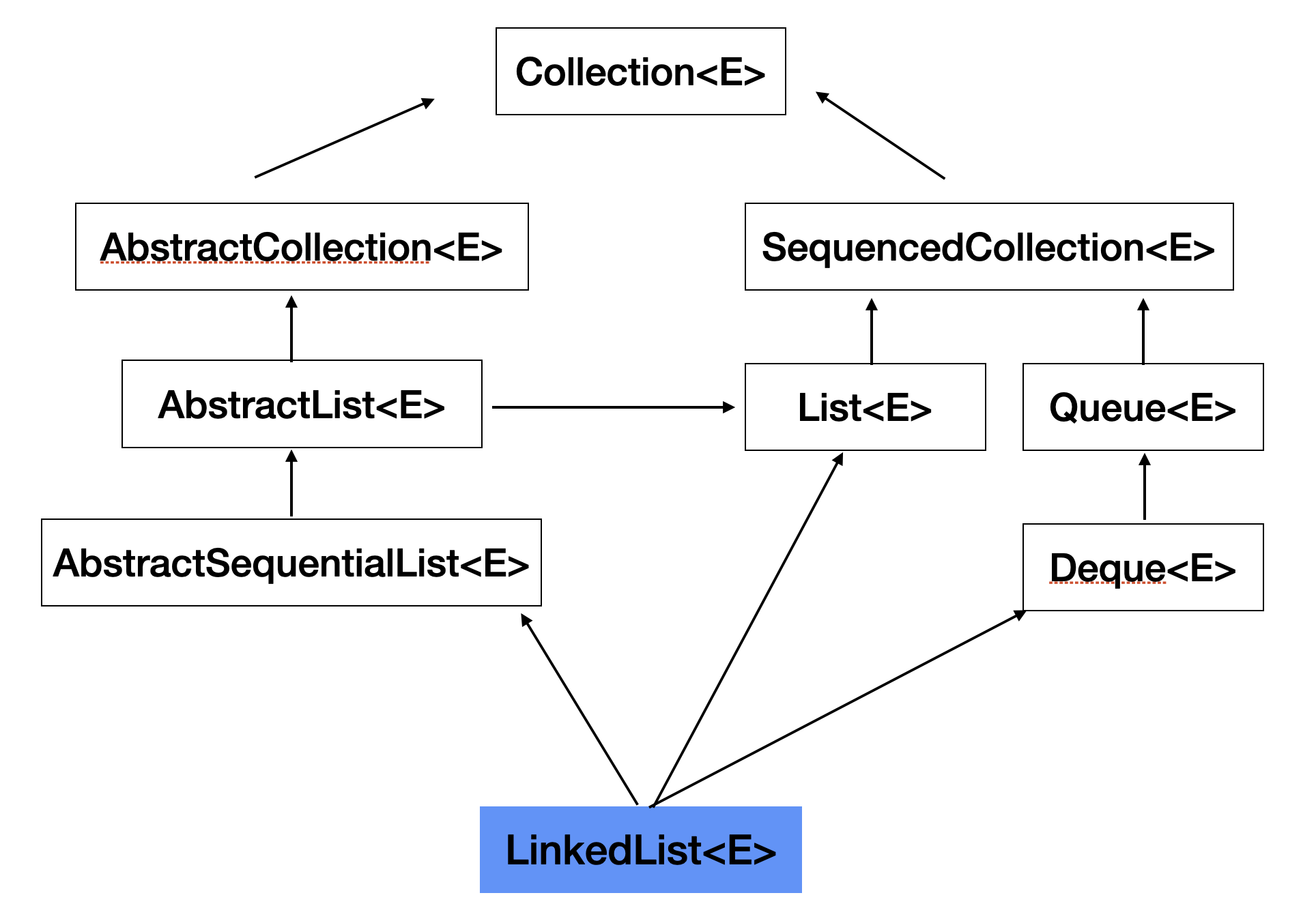
상속 관계
- List와 Deque 인터페이스 구현
- AbstractSequentialList 상속
특징
- 이중 연결 리스트
- 모든 타입 허용 (null 포함)
- 순회가 필요한 경우
동기화 불가
- LinkedList는 동기화를 지원하지 않음
- 따라서 여러 스레드에서 동시에 접근했을 때 어느 한 스레드에서 구조적 수정을 하는 경우 동기화가 필요함
- Collections.synchronizedList()를 통해 동기화 처리 가능
이터레이터
- 이터레이터 생성 후 구조적 수정이 이뤄지면 fail-fast 발생 (
ConcurrentModificationException)
동시성 이슈 해결방안
LinkedList 코드 분석
필드, 내부 클래스
필드
int size: 현재 요소의 개수Node<E> first: head 노드Node<E> last: tail 노드
내부 클래스
- 연결 리스트의 노드를 나타내는 노드 클래스
자바의 LinkedList는 이중 연결 리스트로, Node 클래스는 prev, next 필드를 가지고 있음
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
이터레이터
- DescendingIterator
- ListItr
- LLSpliterator
- RandomAccessSpliterator
뷰
- ReverseOrderLinkedListView
내부 메서드
연결 리스트 요소들의 참조 작업을 내부 메서드를 통해 공통적으로 수행함
void linkFirst(E)
// 연결 리스트의 head 노드에 새 노드를 삽입하는 메서드
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
// 만약 기존 head 노드가 null이라면 연결 리스트에 아무 노드가 없다는 뜻이므로, 삽입하려는 메서드가 head 노드이자 tail 노드가 됨
if (f == null)
last = newNode;
// 그렇지 않다면 기존 head의 prev를 새 노드로 연결시켜줌
else
f.prev = newNode;
size++;
modCount++;
}
void linkLast(E)
// linkFirst와는 반대로, tail 노드에 새 노드를 삽입하는 메서드
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
// 만약 기존 tail 노드가 null이라면 연결 리스트에 아무 노드가 없다는 뜻이므로, 삽입하려는 메서드가 head 노드이자 tail 노드가 됨
if (l == null)
first = newNode;
// 그렇지 않다면 기존 tail 노드의 next를 새 노드로 연결시켜줌
else
l.next = newNode;
size++;
modCount++;
}
void linkBefore(E, Node<E>)
// linkBefore 메서드는 linkFirst와 linkLast 메서드와 달리, 특정 지점에 노드를 삽입하는 메서드로, 매개변수로 받은 succ 노드의 이전(prev)에 새 노드를 삽입함
// succ: successor의 줄임말로 어떤 노드의 다음 노드(next)를 말함
// pred: predecessor의 줄임말로 어떤 노드의 이전 노드(prev)를 말함
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
// succ 노드의 이전 노드를 새 노드로 지정함
succ.prev = newNode;
// 만약 pred(`succ.prev`)가 null인 경우 succ 노드가 head 노드라는 것을 의미하므로 새 노드를 head 노드로 지정함
if (pred == null)
first = newNode;
// 아닌 경우 원래 succ 노드의 이전 노드의 next를 새 노드를 가리키게 함
else
pred.next = newNode;
size++;
modCount++;
}
E unLinkFirst(Node<E>)
// head 노드를 삭제하는 함수
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
// 기존 head 노드의 값을 null 처리(GC)
f.item = null;
f.next = null; // help GC
// head 노드를 기존 head의 다음 노드로 지정하고,
first = next;
// 만약 다음 노드가 null이라면 기존 head 노드를 제외하고 연결 리스트에 아무 노드가 없다는 것이므로 tail 노드도 null 처리
if (next == null)
last = null;
// 아닌 경우 다음 노드의 prev 값을 null 처리
else
next.prev = null;
size--;
modCount++;
return element;
}
E unLinkLast(Node<E>)
// tail 노드를 삭제하는 함수
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
// 기존 tail 노드의 값을 null 처리(GC)
l.item = null;
l.prev = null; // help GC
// tail 노드를 기존 tail 노드의 이전 노드로 지정하고,
last = prev;
// 만약 이전 노드가 null이라면 기존 tail 노드를 제외하고 연결 리스트에 아무 노드가 없다는 것이므로 head 노드도 null 처리
if (prev == null)
first = null;
// 아닌 경우 다음 노드의 next 값을 null 처리
else
prev.next = null;
size--;
modCount++;
return element;
}
E unLink(Node<E>)
// 매개변수로 받은 노드를 삭제하는 함수
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// 먼저 prev 값을 기반으로 다음 노드 연결 처리
// prev 값이 null인 경우 x 노드는 head 노드를 의미하므로, x의 다음 노드를 head로 지정
if (prev == null) {
first = next;
}
// 아닌 경우 x 노드의 이전 노드와 x 노드의 다음 노드를 연결
else {
prev.next = next;
x.prev = null;
}
// 그 다음 next 값을 기반으로 이전 노드 연결 처리
// next 값이 null인 경우 x 노드는 tail 노드를 의미하므로, x의 이전 노드를 tail로 지정
if (next == null) {
last = prev;
}
// 아닌 경우 x 노드의 다음 노드와 x 노드의 이전 노드를 연결
else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
Node<E> node(int)
// 특정 인덱스에 위치한 노드를 반환하는 함수
Node<E> node(int index) {
// assert isElementIndex(index);
// 인덱스의 값이 리스트의 절반보다 작은 경우 head 노드에서 순회
if (index < (size >> 1)) {
Node<E> x = first;
// 배열과 동일하게 0부터 시작
for (int i = 0; i < index; i++)
x = x.next;
return x;
}
// 큰 경우 tail 노드에서 순회
else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
List 인터페이스 구현 코드
삽입
boolean add(E)
// 요소를 삽입하는 메서드
public boolean add(E e) {
// linkLast()에 위임하여 리스트의 맨 마지막에 요소 삽입
linkLast(e);
return true;
}
void add(int, E)
// 특정 인덱스에 노드를 삽입하는 메서드
public void add(int index, E element) {
checkPositionIndex(index);
// 특정 인덱스에 노드를 삽입하는 메서드로 index의 크기에 따라 삽입 위치를 정함
// index가 size와 같은 경우 맨 뒤에 삽입
if (index == size)
linkLast(element);
// 아닌 경우 linkBefore(Node<E>) 메서드를 사용해서 index에 위치한 기존 노드 이전에 삽입
else
linkBefore(element, node(index));
}
boolean addAll(Collection<? extends E>)
// 컬렉션을 통해 노드를 삽입하는 메서드
public boolean addAll(Collection<? extends E> c) {
// addAll(int, Collection<? extends E>)에 위임
return addAll(size, c);
}
addAll(int, Collection<? extends E>)
boolean addAll(int, Collection<? extends E>)
// 컬렉션을 특정 인덱스부터 노드로 삽입하는 메서드
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
// 매개변수로 받은 컬렉션을 배열로 변환 후 길이 체크
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
// 매개변수로 받은 index 값에 따라 pred, succ 노드의 값 지정
// succ: successor의 줄임말로 어떤 노드의 다음 노드(next)를 말함
// pred: predecessor의 줄임말로 어떤 노드의 이전 노드(prev)를 말함
Node<E> pred, succ;
// index가 size와 같은 경우, 맨 뒤에 컬렉션을 삽입하겠다는 의미
// succ 노드는 null
// pred 노드는 tail 노드로 지정
if (index == size) {
succ = null;
pred = last;
}
// 아닌 경우 리스트 중간에 컬렉션을 삽입하겠다는 의미
// node(int) 메서드를 통해 index에 위치한 노드를 succ 노드로, succ 노드의 이전 노드를 pred 노드로 지정
else {
succ = node(index);
pred = succ.prev;
}
// 배열로 변환한 컬렉션 요소들을 새 노드로 삽입
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
// prev 값에 pred 지정, next 값은 null로 지정
Node<E> newNode = new Node<>(pred, e, null);
// pred가 null인 경우, 연결 리스트에 노드가 하나도 없는 경우를 말함
// head 노드에 새 노드를 지정
if (pred == null)
first = newNode;
// 아닌 경우 pred의 next와 새 노드를 연결
else
pred.next = newNode;
// 새 노드를 pred로 지정하여, 다음 생성될 노드가 새 노드와 연결되도록 함
pred = newNode;
}
// 위의 루프문을 돌면 삽입되기 전 연결 리스트의 pred 노드와 컬렉션 요소로 만들어진 새 노드들이 모두 연결된 상태임
// 새로 삽입된 맨 마지막 노드의 next 값은 지정되지 않았기 때문에 이 부분만 처리해주면 됨
// succ의 값이 null인 경우 컬렉션이 리스트의 끝부터 삽입된 것을 의미하므로 새로 삽입된 맨 마지막 노드가 tail 노드가 됨
if (succ == null) {
last = pred;
}
// 아니라면 컬렉션이 중간에 삽입된 것을 의미하므로, 새로 삽입된 맨 마지막 노드와 기존 노드를 연결해줌
else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
void addFirst(E)
// 맨 앞에 삽입하는 메서드
public void addFirst(E e) {
// linkFirst(E) 위임
linkFirst(e);
}
void addLast(E)
// 맨 뒤에 삽입하는 메서드
public void addLast(E e) {
// linkLast(E) 위임
linkLast(e);
}
삭제
E remove(int)
public E remove(int index) {
// 매개변수로 주어진 인덱스의 범위가 적절한지 확인
checkElementIndex(index);
// 자바의 LinkedList는 이중 연결 리스트이기 때문에 노드 연결 해제 작업이 수월함 O(1)
// 대신 인덱스에 위치한 노드를 순회해서 찾아야됨 O(n)
return unlink(node(index));
}
[E unLink(Node
boolean remove(Object)
// Object 타입의 매개변수와 일치하는 노드를 찾아서 삭제하는 메서드
public boolean remove(Object o) {
// 노드는 null 요소를 가질 수 있음
// 만약 매개변수가 null이라면 head 노드부터 tail 노드까지 순회를 돌면서 O(n)
// 노드의 요소가 null인지 체크하고, null이라면 unlink(Node<E>) 메서드를 호출하여 해당 노드 삭제 O(1)
if (o == null) {
// last
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
}
// 마찬가지로 head 노드부터 tail 노드까지 순회를 돌면서 O(n)
// 매개변수와 노드 요소의 값을 비교함
// 만약 동등하다면 unlink(Node<E>) 메서드를 호출하여 해당 노드 삭제 O(1)
else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
// 삭제하지 못한 경우 false 리턴
return false;
}
boolean removeAll(Collection<?>)
// LinkedList는 removeAll() 메서드를 오버라이딩하지 않고
// AbstractCollection.removeAll() 사용
// 매개변수로 주어진 컬렉션의 값과 동등한 요소를 가지고 있는 노드들을 삭제하는 메서드
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
boolean modified = false;
// 이터레이터로 순회
// LinkedList의 ListItr 구현체 사용
Iterator<?> it = iterator();
while (it.hasNext()) {
// 매개변수 컬렉션이 노드의 요소를 포함하고 있는 경우
if (c.contains(it.next())) {
// ListItr의 remove()로 삭제
it.remove();
modified = true;
}
}
return modified;
}
boolean retainAll(Collection<?> c)
// LinkedList는 retainAll() 메서드를 오버라이딩하지 않고
// AbstractCollection.retainAll() 사용
// 매개변수로 주어진 컬렉션의 값과 동등한 요소를 가지고 있지 않은 노드들을 삭제하는 메서드
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
boolean modified = false;
// 이터레이터로 순회
// LinkedList의 ListItr 구현체 사용
Iterator<E> it = iterator();
while (it.hasNext()) {
// 매개변수 컬렉션이 노드의 요소를 포함하고 있지 않은 경우
if (!c.contains(it.next())) {
// ListItr의 remove()로 삭제
it.remove();
modified = true;
}
}
return modified;
}
E removeFirst()
public E removeFirst() {
// head 노드부터 시작
final Node<E> f = first;
// head 노드가 null인 경우 리스트에 노드가 아예 없다는 의미이므로 예외 던짐
if (f == null)
throw new NoSuchElementException();
// unlinkFirst(Node<E>)에게 위임하여 head 노드 삭제
return unlinkFirst(f);
}
[E unLinkFirst(Node
E removeLast()
public E removeLast() {
// tail 노드부터 시작
final Node<E> l = last;
// tail 노드가 null인 경우 리스트에 노드가 아예 없다는 의미이므로 예외 던짐
if (l == null)
throw new NoSuchElementException();
// unlinkLast(Node<E>)에게 위임하여 tail 노드 삭제
return unlinkLast(l);
}
[E unlinkLast(Node
void clear()
// 연결 리스트의 모든 노드를 삭제하는 메서드
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
// head 노드부터 tail 노드까지 돌면서 노드 삭제
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
boolean removeIf(Predicate<? super E>)
// LinkedList는 removeIf() 메서드를 오버라이드하지 않고
// Collection.removeIf() 사용
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
// 이터레이터로 순회
// LinkedList의 ListItr 구현체 사용
final Iterator<E> each = iterator();
while (each.hasNext()) {
// Predicate의 조건에 만족하는 경우
if (filter.test(each.next())) {
// // ListItr의 remove()로 삭제
each.remove();
removed = true;
}
}
return removed;
}
void removeRange(int, int)
// LinkedList는 removeRange() 메서드를 오버라이드하지 않고
// AbstractList.removeRange() 사용
// 다만 protected 접근 제어자이므로 외부에서 접근 불가
// LinkedList 내부에서 따로 사용하지 않음
protected void removeRange(int fromIndex, int toIndex) {
// 시작 인덱스부터 이터레이터 사용
ListIterator<E> it = listIterator(fromIndex);
// fromIndex와 toIndex 사이만 순회하여 노드 삭제
for (int i = 0, n = toIndex - fromIndex; i < n; i++) {
it.next();
it.remove();
}
}
조회
E get(int)
// 매개변수로 받은 인덱스에 위치한 노드의 요소를 반환하는 메서드
public E get(int index) {
// 인덱스 범위가 올바른지 확인
checkElementIndex(index);
// node(int) 메서드를 통해 노드를 찾은 뒤 요소 반환
return node(index).item;
}
[Node
E getFirst()
// head 노드의 요소를 반환하는 메서드
public E getFirst() {
final Node<E> f = first;
// head 노드가 null인 경우 리스트에 노드가 아예 없다는 의미이므로 예외 던짐
if (f == null)
throw new NoSuchElementException();
// head 노드 요소 반환
return f.item;
}
E getLast()
// tail 노드의 요소를 반환하는 메서드
public E getLast() {
final Node<E> l = last;
// tail 노드가 null인 경우 리스트에 노드가 아예 없다는 의미이므로 예외 던짐
if (l == null)
throw new NoSuchElementException();
// tail 노드 요소 반환
return l.item;
}
int indexOf(Object)
// 매개변수와 동등한 값을 요소로 가지고 있는 노드의 인덱스를 반환하는 메서드
public int indexOf(Object o) {
// 맨 앞에서 시작
int index = 0;
// 노드는 null 요소를 가질 수 있음
// 만약 매개변수가 null이라면 head 노드부터 tail 노드까지 순회를 돌면서
// 노드의 요소가 null인지 체크하고, null이라면 해당 인덱스 반환
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
}
// 마찬가지로 head 노드부터 tail 노드까지 순회를 돌면서
// 매개변수와 노드 요소의 값을 비교함
// 만약 동등하다면 해당 인덱스 반환
else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
// 매개변수의 값을 가진 노드가 없는 경우 -1 반환
return -1;
}
int lastIndexOf(Object)
// 매개변수와 동등한 값을 요소로 가지고 있는 노드의 인덱스를 반환하는 메서드
// indexOf(Object)와 반대로 tail 노드부터 순회함
public int lastIndexOf(Object o) {
// 맨 뒤에서 시작
int index = size;
// 노드는 null 요소를 가질 수 있음
// 만약 매개변수가 null이라면 tail 노드부터 head 노드까지 순회를 돌면서
// 노드의 요소가 null인지 체크하고, null이라면 해당 인덱스 반환
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
}
// 마찬가지로 tail 노드부터 head 노드까지 순회를 돌면서
// 매개변수와 노드 요소의 값을 비교함
// 만약 동등하다면 해당 인덱스 반환
else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
boolean contains(Object)
// 매개변수의 값을 요소로 가진 노드가 있는지 확인하는 메서드
public boolean contains(Object o) {
// indexOf(Object) 메서드는 노드가 있는 경우 0보다 같거나 큰 값을 반환함
// 조건에 맞는 경우 true 리턴
return indexOf(o) >= 0;
}
boolean containsAll(Collection<?>)
// LinkedList는 containsAll() 메서드를 오버라이드하지 않고
// AbstractCollection.containsAll() 사용
public boolean containsAll(Collection<?> c) {
// 루프문을 돌면서 값이 포함되어 있는지 확인
for (Object e : c)
// 포함되지 않은 경우 false 리턴
if (!contains(e))
return false;
return true;
}
조작
int set(int, E)
// 매개변수로 주어진 인덱스에 위치한 노드의 요소를 바꾸는 메서드
public E set(int index, E element) {
// 인덱스 범위가 올바른지 확인
checkElementIndex(index);
// node(int) 메서드를 사용해서 인덱스에 위치한 노드 가져옴
Node<E> x = node(index);
E oldVal = x.item;
// 해당 노드 값 변경
x.item = element;
return oldVal;
}
[Node
toArray()
Object[] toArray()
// 리스트의 요소를 배열로 반환하는 메서드
public Object[] toArray() {
// 리스트 크기만큼의 Object[] 배열
Object[] result = new Object[size];
int i = 0;
// head 노드부터 tail 노드까지 순회하면서 각 노드의 요소를 배열에 담음
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}
T[] toArray(T[])
// 매개변수로 받은 배열에 리스트의 요소를 담아 반환하는 메서드
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
// a의 길이가 리스트의 크기보다 작은 경우 a의 사이즈를 늘림
if (a.length < size)
a = (T[]) java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size);
int i = 0;
Object[] result = a;
// head 노드부터 tail 노드까지 순회하면서 각 노드의 요소를 배열에 담음
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
// a의 길이가 리스트의 크기보다 큰 경우 size 인덱스에 null 처리
if (a.length > size)
a[size] = null;
return a;
}
Deque 인터페이스 구현 코드
Deque란
Deque란 Double-Ended Queue의 줄임말로, 양방향 큐를 의미함
- 양방향 큐는 큐의 양쪽 끝에서 요소를 삽입하고 삭제할 수 있음
- 자바의 Deque 인터페이스는 큐와 스택의 모든 기능을 제공하기 때문에 큐, 스택으로 활용 가능
- 대표적인 구현체로는 LinkedList, ArrayDeque(동적 배열 크기 조정, 인덱스 기반 접근)가 있음
LinkedList는 이중 연결 리스트이므로 head 노드는 물론, tail 노드에서도 작업을 처리할 수 있기 때문에
Deque 인터페이스를 구현해서 Deque처럼 사용할 수도 있음
삽입
boolean offer(E)
public boolean offer(E e) {
// 리스트의 맨 뒤에 삽입하는 add(E) 메서드 호출
// LinkedList 타입의 Deque.offer() 메서드는 요소를 맨 뒤에 삽입함
return add(e);
}
boolean offerFirst(E)
public boolean offerFirst(E e) {
// 리스트의 맨 앞에 삽입하는 addFirst(E) 메서드 호출
addFirst(e);
return true;
}
boolean offerLast(E)
public boolean offerLast(E e) {
// offer(E)와 동일하게 리스트의 맨 뒤에 삽입하는 addLast(E) 메서드 호출
addLast(e);
return true;
}
void push(E)
// Stack의 기능을 지원하는 삽입 메서드
public void push(E e) {
// 스택은 First-In, Last-Out의 성질을 가지고 있음
// 따라서 리스트의 맨 앞에 삽입
addFirst(e);
}
삭제
E poll()
public E poll() {
// LinkedList 타입의 Deque.poll() 메서드는 맨 앞의 요소를 삭제함
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
[E unlinkFirst(Node
E pollFirst()
// poll() 메서드와 동일하게 동작
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
[E unlinkFirst(Node
E pollLast()
public E pollLast() {
// 맨 뒤의 요소를 삭제
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
[E unlinkLast(Node
E pop()
// Stack 기능을 지원하는 삭제 메서드
public E pop() {
// 스택은 First-In, Last-Out의 성질을 가지고 있음
// 헤드 노드를 삭제하는 removeFirst() 메서드를 호출하여 가장 마지막에 삽입된 노드 삭제
return removeFirst();
}
remove()
// 삭제 메서드
public E remove() {
// 큐는 FIFO 성질을 가짐
// offer() 메서드에서 맨 뒤에서 삽입하므로 맨 앞에서 삭제
return removeFirst();
}
removeFirstOccurrence(Object)
// 매개변수와 동등한 요소를 가진 노드 중 첫번째 노드를 삭제하는 메서드
public boolean removeFirstOccurrence(Object o) {
// head 노드부터 tail 노드까지 순회하는 remove(Ojbect)에게 위임
return remove(o);
}
removeLastOccurrence(Object)
// Object 타입의 매개변수와 일치하는 노드를 찾아서 삭제하는 메서드
public boolean removeLastOccurrence(Object o) {
// 노드는 null 요소를 가질 수 있음
// 만약 매개변수가 null이라면 tail 노드부터 head 노드까지 순회를 돌면서
// 노드의 요소가 null인지 체크하고, null이라면 해당 노드 삭제
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
return true;
}
}
}
// 마찬가지로 tail 노드부터 head 노드까지 순회를 돌면서
// 매개변수와 노드 요소의 값을 비교함
// 만약 동등하다면 해당 노드 삭제
else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
// 삭제하지 못한 경우 false 리턴
return false;
}
조회
E peek()
// 조회 메서드
public E peek() {
// LinkedList 타입의 Deque.peek() 메서드는 맨 앞의 요소를 조회함
final Node<E> f = first;
return (f == null) ? null : f.item;
}
E peekFirst()
// peek() 메서드와 동일하게 동작
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
E peekLast()
// 맨 뒤의 요소를 조회하는 메서드
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
E elemeent()
// 맨 위의 요소를 조회하는 메서드
public E element() {
return getFirst();
}