index
prometheus
프로메테우스는 시스템 및 애플리케이션의 모니터링과 경보(alerting)을 위한 오픈 소스 도구로 2012년 soundcloud에서 시작되어 2016년 쿠버네티스 이후 두 번째로 호스트된 cncf의 프로젝트로 관리되고 있다
프로메테우스의 핵심 개념은 다음과 같다: 시계열 데이터 저장소, 풀 기반 데이터 수집, promql, 알림, 시각화
times series data source
프로메테우스는 주로 메트릭을 시계열 데이터로써 수집하고 저장하는데, 이는 타임 스탬프와 메트릭 정보를 함께 저장하여 시간에 따른 값의 변화를 추적한다는 의미이다
그리고 필요에 따라 라벨(label)이라고 부르는 키-값 쌍의 데이터도 함께 저장하여 시계열 데이터가 메트릭 이름과 라벨을 통해 식별되도록 한다
pull-based data collecting
프로메테우스는 http 요청을 통해 대상(target)에서 메트릭을 직접 스크랩(scrap)하는 pull 기반 데이터 수집 방식을 채택한다
스크랩 간격은 설정 파일(prometheus)에서 정의할 수 있다
promql (prometheus query language)
프로메테우스는 메트릭을 집계, 분석, 시각화하기 위한 쿼리 언어인 promql을 제공한다
sum(rate(http_requests_total[5m])): 최근 5분 동안의 http 요청 비율
alerting
prometheus 조직의 다른 프로젝트인 alertmanager와 프로메테우스를 통합하여 특정 메트릭의 임계값을 초과할 때 다양한 알림 채널(슬랙, 이메일 등)로 알림을 보낼 수 있다
visualization
프로메테우스 자체적으로 간단한 시각화 기능을 제공한다
이 기능을 주로 사용하기 보단 grafana와 통합하여 시각화 대시보드를 구성한다
components
프로메테우스 생태계는 여러 구성 요소(프로젝트)로 구성되어 있으며 필요에 따라 사용할 수 있다
대부분 go 언어로 작성되어 있으며 정적 바이너리로 배포된다
prometheus server
메트릭을 스크랩하고 시계열 데이터를 저장하는 메인 구성 요소
client libraries
애플리케이션 코드 계측을 위한 프로메테우스 클라이언트, 언어 별로 각 클라이언트를 구현한다
client_java, client_golang, client_rust 등
push gateway
짧은 수명의 배치 작업(batch job) 메트릭을 수집할 때 사용되는 구성 요소
exporters
서드 파티 시스템의 기존 메트릭을 프로메테우스 메트릭으로 내보내는 데 사용되는 구성 요소
HAProxy 또는 리눅스 시스템 통계처럼 프로메테우스가 직접 메트릭을 측정하기 어려운 경우에 주로 사용된다
alertmanager
알림을 관리하는 구성 요소
architecture
아래의 이미지는 프로메테우스와 각 구성 요소 간의 구조를 보여준다
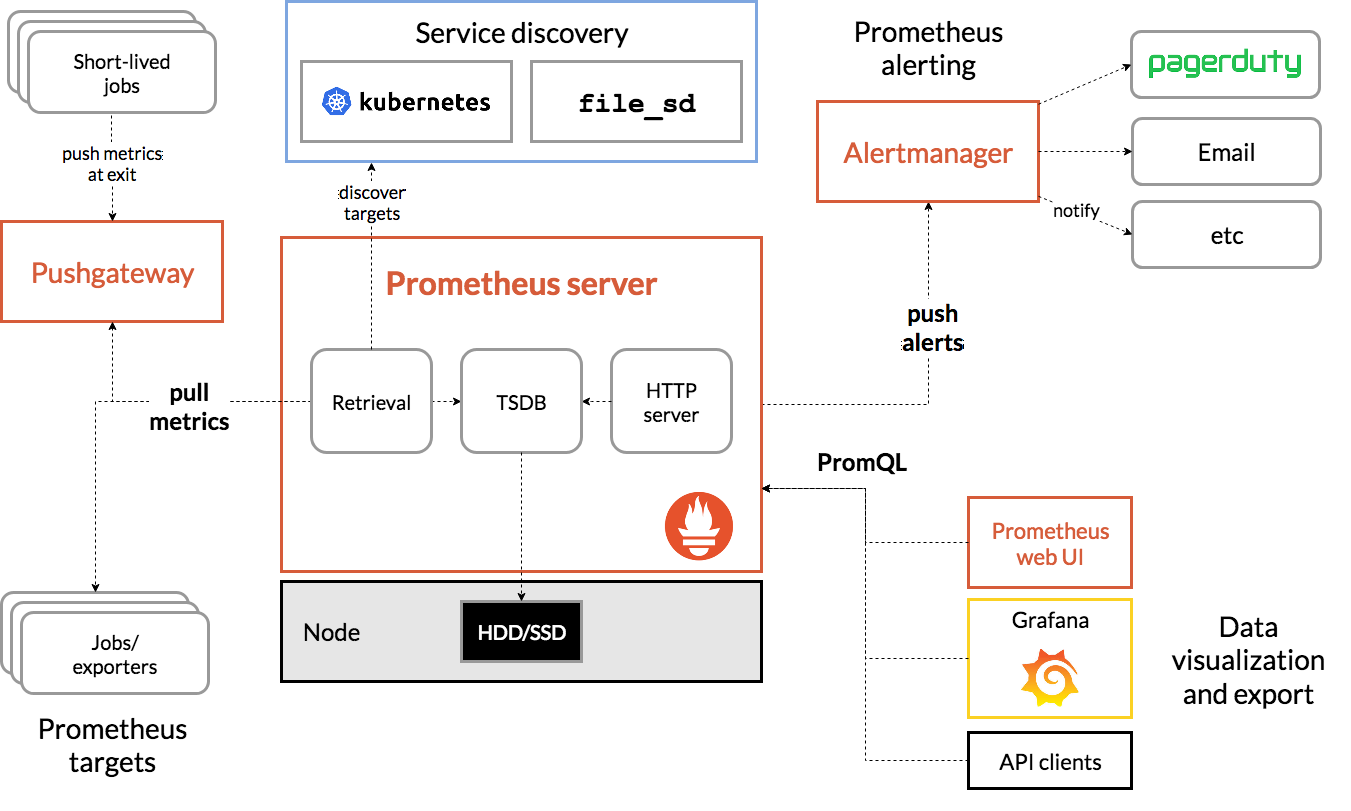
프로메테우스 서버에서 등록된 job들(직접적인 job 또는 push gateway의 short-lived job)으로부터 메트릭을 스크랩한다
스크랩한 샘플들은 모두 로컬에 저장한 뒤 이 데이터들에 대한 집계와 새 시계열을 기록하거나 알림을 생성하기 위해 설정된 규칙을 적용한다
그리고 프로메테우스 웹 ui, 그라파나 또는 다른 api를 통해 수집된 데이터를 시각화한다
use cases
애플리케이션 성능 모니터링(apm - application performance monitoring)
서버 및 인프라 모니터링
컨테이너 및 쿠버네티스 모니터링
알림 시스템 구축
서비스 레벨 목표(slo - service level objectives) 및 서비스 레벨 지표(sli - service level indicators) 측정
props and limits
장점
- 강력한 시계열 데이터 수집 및 분석할 수 있다
- 설정 파일을 기반으로 간편하게 모니터링을 구성할 수 있다
- promql을 통한 복잡한 쿼리를 만들 수 있다
- 다양한 exporter를 통한 폭넓은 모니터링이 가능하다
한계
- 분산 저장소를 지원하지 않고 단일 인스턴스에만 데이터를 저장한다
- 고가용성을 위해 추가적인 모니터링 시스템을 필요로 한다
- 장기 데이터 보관 시 스토리지 관리가 필요하다
- 큰 규모의 인프라에서는 성능 이슈가 발생할 수 있다
other tools
thanos, cortex: 프로메테우스의 확장성과 고가용성 한계점을 해결하는 모니터링 프로젝트
opentelemetry: observability을 위한 통합 표준을 제공하며 프로메테우스와 통합할 수 있다
prometheus operator: 쿠버네티스 환경에서 prometheus를 쉽게 배포하고 관리할 수 있도록 도와준다